以TextCNN为例学习CNN
发布时间:2024-01-07 19:55:03
转载请注明出处:https://blog.csdn.net/qq_33427047/article/details/80393972
以TextCNN为例学习CNN
- TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 Convolutional Neural Networks for Sentence Classification 一文中提出. 是2014年的算法.
- CNN 的主要过程如下:
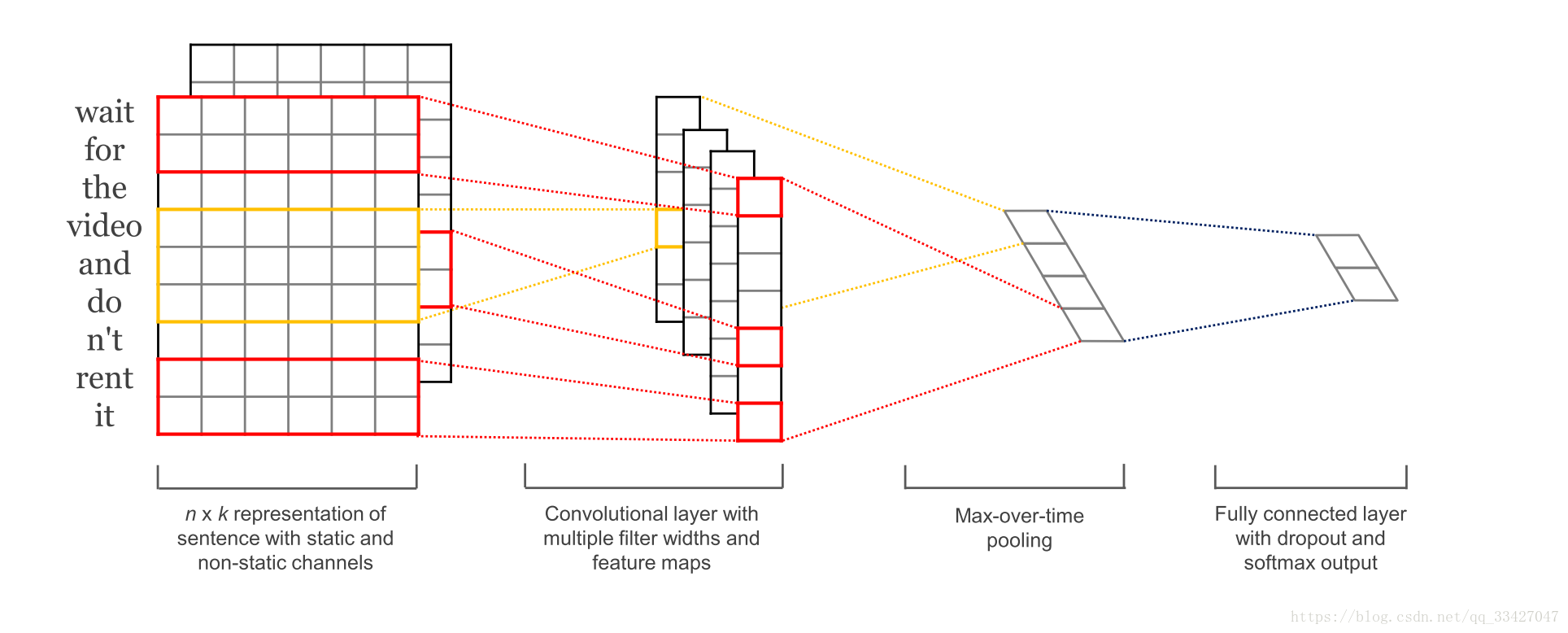
解读TextCNN
- TextCNN源码 https://github.com/dennybritz/cnn-text-classification-tf
- 以下1部分转载至 http://www.dataguru.cn/forum.php?mod=viewthread&tid=637971&extra=page=1&page=1
1 这个class的主要作用是什么?
TextCNN类搭建了一个最basic的CNN模型,有input layer,convolutional layer,max-pooling layer和最后输出的softmax layer.
但是又因为整个模型是用于文本的(而非CNN的传统处理对象:图像),因此在cnn的操作上相对应地做了一些小调整:
- 对于文本任务,输入层自然使用了word embedding来做input data representation
- 接下来是卷积层,大家在图像处理中经常看到的卷积核都是正方形的,比如4*4,然后在整张image上沿宽和高逐步移动进行卷积操作。但是nlp中输入的”image”是一个词矩阵,比如n个words,每个word用200维的vector表示的话,这个”image”就是n*200的矩阵,卷积核只在高度上已经滑动,在宽度上和word vector的维度一致(=200),也就是说每次窗口滑动过的位置都是完整的单词,不会将几个单词的一部分”vector”进行卷积,这也保证了word作为语言中最小粒度的合理性。(当然,如果研究的粒度是character-level而不是word-level,需要另外的方式处理)
- 由于卷积核和word embedding的宽度一致,一个卷积核对于一个sentence,卷积后得到的结果是一个vector, shape=(sentence_len - filter_window + 1, 1),那么,在max-pooling后得到的就是一个Scalar.所以,这点也是和图像卷积的不同之处,需要注意一下
- 正是由于max-pooling后只是得到一个scalar,在nlp中,会实施多个filter_window_size(比如3,4,5个words的宽度分别作为卷积的窗口大小),每个window_size又有num_filters个(比如64个)卷积核。一个卷积核得到的只是一个scalar太孤单了,智慧的人们就将相同window_size卷积出来的num_filter个scalar组合在一起,组成这个window_size下的feature_vector
- 最后再将所有window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入
一个卷积核对于一个句子,convolution后得到的是一个vector;max-pooling后,得到的是一个scalar
总结一下这个类的作用就是:搭建一个用于文本数据的CNN模型!
2 模型参数
- 关于model
- filter_sizes: 3,4,5, Comma-separated filter sizes (default: ‘3,4,5’)
- num_filters: 128, Number of filters per filter size (default: 128)
- dropout_keep_prob: 0.5, Dropout keep probability (default: 0.5)
- l2_reg_lambda: 0.0, L2 regularization lambda (default: 0.0)
- 关于training
- batch_size: 64, Batch Size (default: 64)
- num_epochs: 200, Number of training epochs (default: 200)
- evaluate_every: 100, Evaluate model
文章来源:https://blog.csdn.net/qq_33427047/article/details/80393972
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- 亚马逊鲲鹏系统给我带来的真实体验感
- GNN Torch functions
- pytorch中nonzero()的用法
- fill的用法
- Pytorch中torch.nonzero()函数解析
- ECMAScript 6 Promise - 通过Promise输出题理解Promise
- java 集成 layIm 聊天工具
- Sql server 日期转换处理大全
- 宝塔面板部署laravel项目填坑总结[持续更新]
- Redis哈希槽,对于哈希槽的理解,以及高并发情况下哈希槽不够的情况讲解,热点缓存的解决思路
- npm依赖包bin文件路径问题
- 抖店一件代发怎么做?需要粉丝基数吗?
- mac系统下配置域名映射关系
- 【C++】String类的实现
- 安全用电监测预警系统-保障电力设施安全运行